Anyshare 开放与集成方案
Anyshare 开放与集成方案
1. 概述
1.1 方案背景与目标
Anyshare 作为企业级文档管理与协作平台,积累了海量的非结构化文档数据。随着 AI 技术的快速发展,如何高效地挖掘文档价值、提供智能化的搜索与问答能力,成为企业数字化转型的关键需求。
本文档旨在开放 Anyshare 的核心能力,通过一系列标准化接口,使开发者能够:
1:获取文档元数据: 获取文档的基础信息,包含文件名,摘要,编目,标签等。
2. 文档解析全文获取:获取文档的解析全文,包含各类office文档或音视频文件中的文本字体,内嵌图片中文字。
3. 文档切片召回: 基于关键字召回和向量召回等策略,从海量文档中根据用户输入召回相关切片以及召回指定切片的上下文切片。
4. 小模型访问: 提供文本embedding、文本reranker、图片OCR、音视频文件解析等小模型访问接口。
5. 对接外部Agent平台:支持与 Dify、HiAgent、外部系统通过配置或代码集成。
6. 内置知识助手能力访问:基于开放接口提供AnyShare 知识助手内置技能。包含你问我答,精准搜索,规则式审阅,专家撰写等原子技能。
1.3 核心价值
- 开放性与标准化:所有接口遵循 RESTful 规范,提供详细的 OpenAPI 文档。
- 安全可控:支持应用账号访问控制,确保数据权限与审计。
- 高性能与可扩展:基于分布式架构,支持海量并发与水平扩展。
- AI 原生:内置向量检索、模型推理等 AI 能力,降低集成复杂度。
2. 整体架构
2.1 系统开放架构
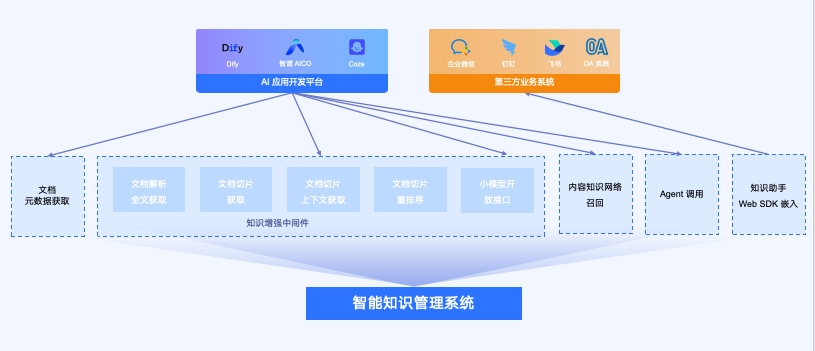
| 模块 | 接入描述 | 接入方式 | 认证方式 | 账户类型 | |
|---|---|---|---|---|
| 文档元数据引用 | 是指可以通过文档中心引擎接口来获取文档元数据和文件列表相应操作。 | restful api | Bearer token | 系统账户和应用账户 |
| 知识增强中间件 | 包含文档的解析全文获取,文档切片召回,文档切片上下文召回,文档切片重排序,小模型访问接口 | restful api | Bearer token | 系统账户和应用账户 |
| 内容知识网络召回 | 包含文档的解析全文获取,文档切片召回,文档切片上下文召回,文档切片重排序,embedding,reranker,ocr,speech | restful api | Bearer token | 系统账户和应用账户 |
| Agent调用 | 可以通过开放接口和智能体进行对话,支持知识助手和自定义智能体。 | restful api | Bearer token | 系统账户和应用账户 |
| SDK嵌入 | Anyshare 提供前端SDK,在Web页面中直接集成相应智能体能力。 | restful api | Bearer token | 系统账户和应用账户 |
3. 接口总览
3.1 接口分类
| 类别 | 功能描述 | 核心接口示例 | 支持应用账号 |
|---|---|---|---|
| 文件元数据 | 获取文档基本信息(名称、大小、路径等) | GET /api/efast/v1/file/metadata |
是 |
| 文件内容解析 | 获取文档解析后的全文结构化内容 | GET /api/ecoindex/v1/subdocfetch/{type} |
是 |
| 召回 | 切片召回 | POST /api/ecosearch/v1/slice-search |
是 |
| 召回 | 混合召回 | POST /api/intelli-search/v1/mf/retrieval |
是 |
| 召回 | 切片上下文获取 | POST /ecoindex/v1/index/slicefetch |
是 |
| 小模型能力 | 文本向量化 | POST /api/intelli-search/v1/mf/embeddings |
是 |
| 小模型能力 | 重排序 | POST /api/intelli-search/v1/mf/rerank_hybrid |
是 |
| 小模型能力 | OCR | POST /api/intelli-search/v1/mf/ocr |
是 |
| 小模型能力 | 音视频转文字 | POST /api/intelli-search/v1/mf/speech |
是 |
| Dify集成 | 对接 Dify 等外部知识库系统 | POST /api/intelli-search/v1/mf/dify/retrieval |
是 |
| Agent 调用 | 代理执行指定 Agent 任务 | POST /api/intelli-search/v1/anydata-delegate/{agent_id} |
是 |
| Bot 调用 | 与聊天机器人交互(v2 叠加返回) | POST /api/intelli-search/v2/bots/{bot_id}/chat |
是 |
| Bot 调用 | 与聊天机器人交互(v3 增量返回) | POST /api/intelli-search/v3/bots/{bot_id}/chat |
是 |
3.2 认证与授权
所有接口均需通过身份验证,支持两种方式:
使用应用账号进行认证(推荐):
a. 向管理员申请应用账户,获得应用账号的app_id和app_secret,并按照需要访问的文档库的权限,请求管理员给应用账号分配令牌申请权限和文档库访问权限。
b. 通过应用账户认证接口,获取应用账户的Bearer Token。
接口请求示例:1
2
3
4curl -X POST 'https://stys.aishu.cn/oauth2/token'
-H 'Content-Type: application/x-www-form-urlencoded'
-u '16967a9d-64ec-4f27-a876-ef9bb566a6a5:zjsgat'
--basic --data-urlencode 'grant_type=client_credentials'返回参数示例:
1
2
3
4
5
6{
"access_token": "ory_at_xxx",
"expires_in": 3599,
"scope": "",
"token_type": "bearer"
}其中,access_token 即为应用账户的 token,expires_in指 token 的过期时间,默认一小时过期,如果想延长 Token 的过期时间,可以使用续期接口进行 token 续期。
- 调用接口时在 HTTP Header 中携带:
Authorization: Bearer {access_token}
c. V7067 后,应用账户支持长期 Token(管理员通过管理控制台进行创建),方便外部 AI 应用简化认证工作。
- 调用接口时在 HTTP Header 中携带:
用户令牌认证:
- 用户登录 Anyshare后获取的个人访问令牌
- 适用于用户直接操作的场景
- 权限受用户角色及文档访问控制列表(ACL)限制
注意:部分接口仅支持应用账号访问,具体见各接口说明。生产环境必须使用 HTTPS 保证传输安全。
4. 详细接口说明
4.1 文件元数据接口
接口:获取文档元数据
- 接口地址:
GET /api/efast/v1/file/metadata - 接口说明:根据文档 GNS(全局命名空间)路径获取文档的基本元数据信息。
- 是否支持应用账号访问:是
- 请求参数:
参数名 类型 必填 说明 gnsstring 是 文档的 GNS 路径 - 响应示例:
1
2
3
4
5
6
7
8
9
10
11
12{
"doc_id": "gns://...",
"doc_name": "项目计划书.docx",
"doc_size": 102400,
"doc_path": "/部门/项目/",
"created_by": "user001",
"created_at": 1672531200000,
"modified_by": "user002",
"modified_at": 1672617600000,
"mime_type": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"md5": "a1b2c3d4e5f678901234567890123456"
} - 补充说明:该接口返回的元数据不包含文档内容,仅用于展示或筛选。
4.2 文件内容解析接口
接口:获取文档全文
- 接口地址:
GET /api/ecoindex/v1/subdocfetch/{type} - 接口说明:获取文档的结构化全文内容。当
type=full_structed_text时,返回文档的结构化文本(包含内嵌图片内容)。 - 是否支持应用账号访问:是
- 路径参数:
参数名 类型 必填 说明 typestring 是 内容类型,目前支持 full_structed_text - 查询参数:
参数名 类型 必填 说明 gnsstring 是 文档 GNS 路径 - 响应示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20{
"doc_id": "gns://...",
"content": [
{
"type": "heading",
"level": 1,
"text": "第一章 项目概述"
},
{
"type": "paragraph",
"text": "本项目旨在开发新一代智能文档平台..."
},
{
"type": "table",
"rows": 3,
"columns": 2,
"data": [["姓名", "职位"], ["张三", "项目经理"], ["李四", "架构师"]]
}
]
} - 补充说明:该接口会对文档进行深度解析,提取语义结构,适用于需要文档内容的智能处理场景。
4.3 搜索与召回接口
4.3.1 混合召回(RFF)
- 接口地址:
POST /api/intelli-search/v1/mf/retrieval - 接口说明:混合检索(RFF),支持关键字召回、向量召回、全文召回等多种检索方式的融合。
- 是否支持应用账号访问:是
- 请求体:
1
2
3
4
5
6
7{
"query": "搜索关键词",
"embedding": [0.1, 0.2, ...],
"ranges": ["gns://path1", "gns://path2"],
"limit": 10,
"threshold": 0.7
} - 响应:返回融合后的检索结果,包含相关性评分。
4.3.2 两路召回(关键字+向量)
- 接口地址:
POST /api/ecosearch/v1/slice-search - 接口说明:同时执行关键字召回和向量召回,返回两路结果。支持分页滚动(scroll)。
- 是否支持应用账号访问:是
- 功能:根据 token,召回 token 能访问的文档中心的相关文档切片、wikidoc 的相关切片、faq 的相关切片。
- 接口详细说明:
请求参数:
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
limit |
integer | 否 | 召回数量限制,仅对 doc 类型生效,对 WikiDoc 和 faq 无效 |
text |
string | 否 | 搜索的文本,用于进行关键字匹配 |
embedding |
number[] | 否 | 向量,用于进行向量匹配,默认768维度 |
ranges |
string[] | 否 | 召回范围列表,仅支持文档中心的文件或文件夹 GNS 路径 |
condition |
object | 否 | 召回条件,如文件扩展名过滤 |
item_output_type |
string[] | 否 | 召回类型,可选 "faq"、"doc",无法限制 WikiDoc |
item_output_detail |
object | 否 | 输出详情类型,候选值为”title”,”content”,仅对 item_output_type 为 faq 生效,限定使用faq的 标题或者内容进行匹配 |
timeout |
integer | 否 | 超时时间(毫秒),默认 1000 |
scroll_id |
string | 否 | 分页上下文标记,首次调用不传或传空字符串 |
bot_rev |
string | 否 | 指定 bot 的数据源或者数据集进行召回,可为空,不推荐使用 |
调用说明(以下说明都是在 text、embedding 为空,doc_id 不为空的场景下):
- 首次调用接口,不要传
scroll_id或者传空字符串,否则会返回报错。 - 首次调用接口会在 response 中返回
scroll_id字段,接下来的请求需带上此参数。 - 必须保证在一分钟内使用这个参数进行后续请求,否则上下文参数会过期(每次调用都会刷新过期时间)。
- 当返回的
doc数组为空时,所有符合条件的数据都已经遍历完成,可停止后续调用。
响应示例:
1 | |
其中sparse_results 表示稀疏结果,代表使用 text 作为关键字召回的内容,
其中dense_results 表示稠密结果,代表使用 embedding 作为向量召回的内容,
4.3.3 切片上下文获取
- 接口地址:
POST /ecoindex/v1/index/slicefetch - 接口说明:根据指定的切片信息,获取其前后相邻的切片(上下文)。。
- 是否支持应用账号访问:是
- 接口详细使用示例:
请求参数:
| 字段 | 类型 | 必填 | 说明 |
|---|---|---|---|
index |
string | 是 | 索引名,候选值为"anyshare_slice_vector"(旧切片索引)或 "anyshare_bot"(bot 切片索引) |
doc_info |
object[] | 是 | 文档信息数组 |
doc_info 对象结构:
| 字段 | 类型 | 说明 |
|---|---|---|
docid |
string | 文档 GNS |
segmentid |
integer | 文档段 ID |
before_step |
integer | 向前挖掘的段个数 |
after_step |
integer | 向后挖掘的段个数 |
响应示例:
1 | |
备注:当 before_step = 0,after_step = 0,会返回该文档的所有切片。
4.3.4 切片重排
- 接口地址:
POST /api/intelli-search/v1/mf/rerank_hybrid - 接口说明:将召回的切片进行 Rerank 重排,然后对重排后的切片做上下文补全,最后按文档进行分组。
- 是否支持应用账号访问:是
- 请求体:
1
2
3
4
5{
"slices": ["slice_id_1", "slice_id_2"],
"query": "用户问题",
"group_by_doc": true
}
4.4 小模型能力接口
4.4.1 文本向量化
- 接口地址:
POST /api/intelli-search/v1/mf/embeddings - 接口说明:将输入的文本转换为高维向量表示,用于向量检索或相似度计算。
- 是否支持应用账号访问:是
- 请求体:
1
2
3
4
5{
"texts": ["文本1", "文本2"],
"model": "bge-large-zh", // 可选,默认使用配置的模型
"normalize": true // 可选,是否归一化
} - 响应:
1
2
3
4
5{
"embeddings": [[0.1, 0.2, ...], [0.3, 0.4, ...]],
"model": "bge-large-zh",
"dims": 1024
}
4.4.2 文本重排(Rerank)
- 接口地址:
POST /api/intelli-search/v1/mf/rerank - 接口说明:对一组文本与查询的相关性进行重排序,返回相关性分数。
- 是否支持应用账号访问:是
- 请求体:
1
2
3
4
5{
"query": "用户查询",
"documents": ["文档1内容", "文档2内容"],
"top_k": 5
} - 响应:
1
2
3
4{
"scores": [0.95, 0.87],
"indices": [0, 1]
}
4.4.3 OCR 识别
- 接口地址:
POST /api/intelli-search/v1/mf/ocr - 接口说明:对图片文件进行光学字符识别,提取文本内容。
- 是否支持应用账号访问:是
- 请求体(form-data):
file: 图片文件(PNG、JPG、PDF 等)language: 可选,语言代码(如zh、en)
- 响应:
1
2
3
4
5{
"text": "识别出的文本内容",
"language": "zh",
"confidence": 0.98
}
4.4.4 音视频处理
- 提交处理任务:
POST /api/intelli-search/v1/mf/speech/task - 获取任务结果:
GET /api/intelli-search/v1/mf/speech/task/result/{task_id} - 接口说明:提交音视频文件,提取其中的音频并转写成文本。
- 是否支持应用账号访问:是
- 请求体(form-data):
file: 音视频文件task_type:speech2text
- 响应(提交任务):
1
2
3
4{
"task_id": "task_123456",
"status": "pending"
} - 响应(获取结果):
1
2
3
4
5
6
7
8
9{
"task_id": "task_123456",
"status": "completed",
"result": {
"text": "转写后的文本",
"duration": 120.5,
"language": "zh"
}
}
4.5 外部知识库集成接口
接口:Dify 外部知识库召回
- 接口地址:
POST /api/intelli-search/v1/mf/dify/retrieval - 接口说明:将 Anyshare 的文档库、wikidoc、faq 的切片信息,通过外接知识库的方式,提供给 Dify 进行召回。
- 是否支持应用账号访问:是
- 逻辑设计:
- 请求体:遵循 Dify 知识库检索接口规范。
- 响应:按照 Dify 的返回接口格式返回对应的切片数据。
4.6 Agent 调用接口
接口:AS Agent 调用
- 接口地址:
POST /api/intelli-search/v1/anydata-delegate/{agent_id} - 接口说明:代理调用指定 ID 的 Agent,执行相应的数据处理或分析任务。
- 是否支持应用账号访问:是
- 路径参数:
参数名 类型 说明 agent_idstring Agent 的唯一标识 - 请求体:根据具体 Agent 的定义传入参数。
- 响应:Agent 执行结果,格式由 Agent 定义。
4.7 Bot 聊天接口
4.7.1 V2 Chat(叠加返回)
- 接口地址:
POST /api/intelli-search/v2/bots/{bot_id}/chat - 接口说明:与指定 ID 的聊天机器人进行对话,返回完整的响应内容。
- 是否支持应用账号访问:是
- 路径参数:
参数名 类型 说明 bot_idstring 聊天机器人的唯一标识 - 请求体:
1
2
3
4
5{
"message": "用户输入的问题",
"conversation_id": "可选,会话ID",
"stream": false // 是否流式返回
} - 响应:
1
2
3
4
5{
"response": "机器人的完整回答",
"conversation_id": "会话ID",
"references": ["文档引用1", "文档引用2"]
}
4.7.2 V3 Chat(增量 diff 返回)
- 接口地址:
POST /api/intelli-search/v3/bots/{bot_id}/chat - 接口说明:与 V2 类似,但采用增量返回方式,适用于需要实时显示生成过程的场景。
- 是否支持应用账号访问:是
- 请求体:支持
stream=true参数,启用 Server-Sent Events (SSE) 流式返回。 - 响应格式:当
stream=true时,返回多个 SSE 事件,每个事件包含文本增量。
5. 开发指南
5.1 环境准备
5.1.1 申请访问权限
- 联系 Anyshare 管理员创建应用账号,获取
app_id和app_secret。 - 确定需要访问的文档范围(GNS 路径列表)。
- 获取 API 网关地址(如
https://api.anyshare.example.com)。
5.1.2 开发环境配置
- HTTPS 证书:确保客户端信任 Anyshare 服务器的 TLS 证书。
- 网络连通性:确认客户端可以访问 API 网关地址(可能需要配置防火墙规则)。
- SDK/工具:
- 推荐使用 OpenAPI Generator 根据 OpenAPI 文档生成客户端代码。
- 或直接使用 HTTP 客户端库(如 Python
requests、Gonet/http、JavaOkHttp)。
5.2 认证配置
5.2.1 获取访问令牌(应用账号)
1 | |
响应示例:
1 | |
5.2.2 调用接口(携带令牌)
1 | |
5.3 调用示例
5.3.1 Python 示例(获取文档元数据)
1 | |
5.3.2 Python 示例(切片召回)
1 | |
5.3.3 使用 scroll 进行分页遍历
1 | |
5.4 错误处理
5.4.1 常见 HTTP 状态码
| 状态码 | 含义 | 处理建议 |
|---|---|---|
| 200 | 成功 | 正常处理响应数据 |
| 400 | 非法请求 | 检查请求参数格式、必填字段 |
| 401 | 未授权 | 检查访问令牌是否有效、是否过期 |
| 403 | 无法执行此操作 | 检查应用账号是否有该文档的访问权限 |
| 404 | 资源不存在 | 检查文档 GNS 路径是否正确 |
| 500 | 内部错误 | 联系管理员或稍后重试 |
5.4.2 错误响应格式
所有错误均返回统一格式:
1 | |
处理建议:
- 根据
code判断具体错误类型。 - 查看
detail字段获取额外信息。 - 对于 5xx 错误,建议实现重试机制(指数退避)。
5.5 最佳实践
令牌管理:
- 缓存访问令牌,避免频繁申请。
- 在令牌过期前(如
expires_in的 90%)主动刷新。
性能优化:
- 合理设置
limit参数,避免单次请求数据量过大。 - 使用
scroll分页处理大量数据,而非一次性拉取。 - 对频繁查询的结果实施本地缓存(注意数据实时性要求)。
- 合理设置
容错与重试:
- 对网络超时、5xx 错误实现自动重试(建议最多 3 次)。
- 使用连接池复用 HTTP 连接。
安全建议:
- 严禁在客户端代码中硬编码
app_secret。 - 使用环境变量或密钥管理服务存储敏感信息。
- 定期轮换
app_secret。
- 严禁在客户端代码中硬编码
日志与监控:
- 记录关键操作的请求/响应日志(脱敏敏感数据)。
- 监控接口成功率、响应时间等指标。
6 更新日志
| 版本 | 日期 | 更新内容 |
|---|---|---|
| v1.0 | 2024-01-01 | 初始版本发布,包含基础接口 |
| v1.1 | 2024-03-15 | 新增 Dify 集成接口、Agent 调用接口 |
| v1.2 | 2024-06-30 | 新增 Bot V3 聊天接口,优化检索性能 |